Reducing the aggresive learning rate decay in Adagrad using the twin sibling of Adadelta
In the Adadelta post, we have discussed the limitations of the Adagrad algorithm, the rapid decay of the learning rate. Adadelta solves limitation by calculating the average squared of the decayed gradients over time.
RMSprop also solves the limitation of Adagrad just like Adadelta. Unlike Adadelta The only difference is that RMSprop uses the learning rate value, and divides it with the root mean squared of the decayed gradients. This algorithm was proposed independently by Geoffrey Hinton around the same time as Adagrad. However, this algorithm was never published.
The parameter update rule is expressed as
where
Collectively, , the decayed gradients up to time , can be expressed as follows:
where
Since there are two parameters, we need determine is the gradient of the cost function at time w.r.t. to the intercept , and is the gradient of the cost function at time w.r.t. to the coefficient .
First, First, calculate the intercept and the coefficient gradient. Notice that the intercept gradient is the predicion error.
error = prediction - y[random_index]new_intercept_gradient = errornew_coefficient_gradient = error * x[random_index] Second, calculate the running average of the squared gradients .
can be written as np.mean(df['intercept_gradient'].values ** 2).
mean_squared_intercept = (0.9 * np.mean(df['intercept_gradient'].values ** 2)) + (0.1 * new_intercept_gradient ** 2)mean_squared_coefficient = (0.9 * np.mean(df['coefficient_gradient'].values ** 2)) + (0.1 * new_coefficient_gradient ** 2)Lastly, update the parameters immediately using the calculation we have done above.
intercept -= (learning_rate / np.sqrt(mean_squared_intercept + eps)) * new_intercept_gradientcoefficient -= (learning_rate / np.sqrt(mean_squared_coefficient + eps)) * new_coefficient_gradient
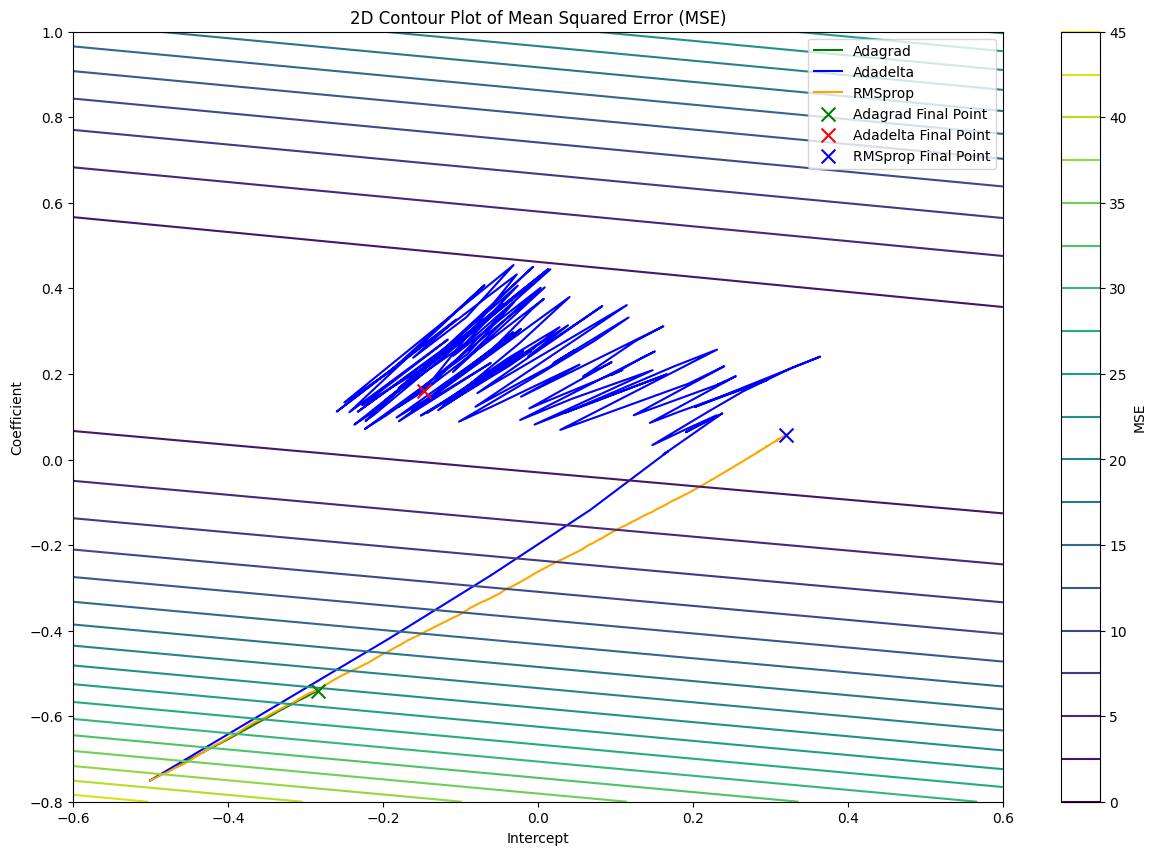
From the graph, we can see that Adagrad struggles to reach the bottom of the cost function in 150 iterations. Unlike Adagrad, Adadelta and RMSprop can reach the bottom of the cost function easily. However, the pathway of Adadelta is noisy compared to RMSprop, and RMSprop is more stable and direct compared to the other two algorithms.
def rmsprop(x, y, df, epoch=150, learning_rate=0.01, eps=1e-8): intercept, coefficient = -0.5, -0.75
random_index = np.random.randint(len(x)) prediction = predict(intercept, coefficient, x[random_index]) error = prediction - y[random_index] mse = (error ** 2) / 2 df.loc[0] = [intercept, coefficient, error, error * x[random_index], mse]
for epoch in range(1, epoch + 1): random_index = np.random.randint(len(x)) prediction = predict(intercept, coefficient, x[random_index]) error = prediction - y[random_index]
new_intercept_gradient = error new_coefficient_gradient = error * x[random_index]
mean_squared_intercept = (0.9 * np.mean(df['intercept_gradient'].values ** 2)) + (0.1 * new_intercept_gradient ** 2) mean_squared_coefficient = (0.9 * np.mean(df['coefficient_gradient'].values ** 2)) + (0.1 * new_coefficient_gradient ** 2)
intercept -= (learning_rate / np.sqrt(mean_squared_intercept + eps)) * new_intercept_gradient coefficient -= (learning_rate / np.sqrt(mean_squared_coefficient + eps)) * new_coefficient_gradient
mse = ((prediction - y[random_index]) ** 2) / 2 df.loc[epoch] = [intercept, coefficient, new_intercept_gradient, new_coefficient_gradient, mse]
return df