Parameter updates with unique learning rate for each parameter
Remember from the SGD with Nesterov post, we could minimize the cost function effeciently with less oscillations by taking consideration of the future gradient. The pathway to the local minima resembles a ball going down a hill in real life, much better than SGD with Momentum. However, the learning rate is still fixed for all parameters.
In this post, we will discuss the Adagrad optimization algorithm, which could help us to adapt the learning rate for each parameter. Meaning, each parameter will have its own learning rate. In addition to that, parameters that are updated frequently will experience smaller updates. While the parameters that are updated infrequently will experience larger updates.
The parameter update rule is expressed as
where
Since we only have two parameters, we are going to need to represent the gradient of the cost function with respect to the intercept, and to represent the gradient of the cost function with respect to the coefficient. These two can be expressed as follows:
Notice in the parameter update rule, Adagrad eliminates the need to manually tune the learning rate for each parameter by dividing the learning rate by the square root of the sum of the squares of the gradients up to time . In most cases, the learning rate value can be set to .
From the equation above, we could see that the learning rate is divided by . Meaning that, the learning rate will decrease rapidly as increases. Note that increases as the number of iterations increases. Thus, the parameters that are updated infrequently will experience larger updates and vice versa.
First, calculate the intercept and the coefficient gradients. Notice that is just the prediction error at time .
error = prediction - y[random_index]
intercept_gradient = errorcoefficient_gradient = error * x[random_index]Second, calculate the sum of the squares of the gradients up to time and accumulate it over time.
accumulated_squared_intercept_gradient += intercept_gradient ** 2accumulated_squared_coefficient_gradient += coefficient_gradient ** 2Finally, update the intercept and the coefficient.
intercept -= (learning_rate / np.sqrt(accumulated_squared_intercept + eps)) * intercept_gradientcoefficient -= (learning_rate / np.sqrt(accumulated_squared_coefficient + eps)) * coefficient_gradient
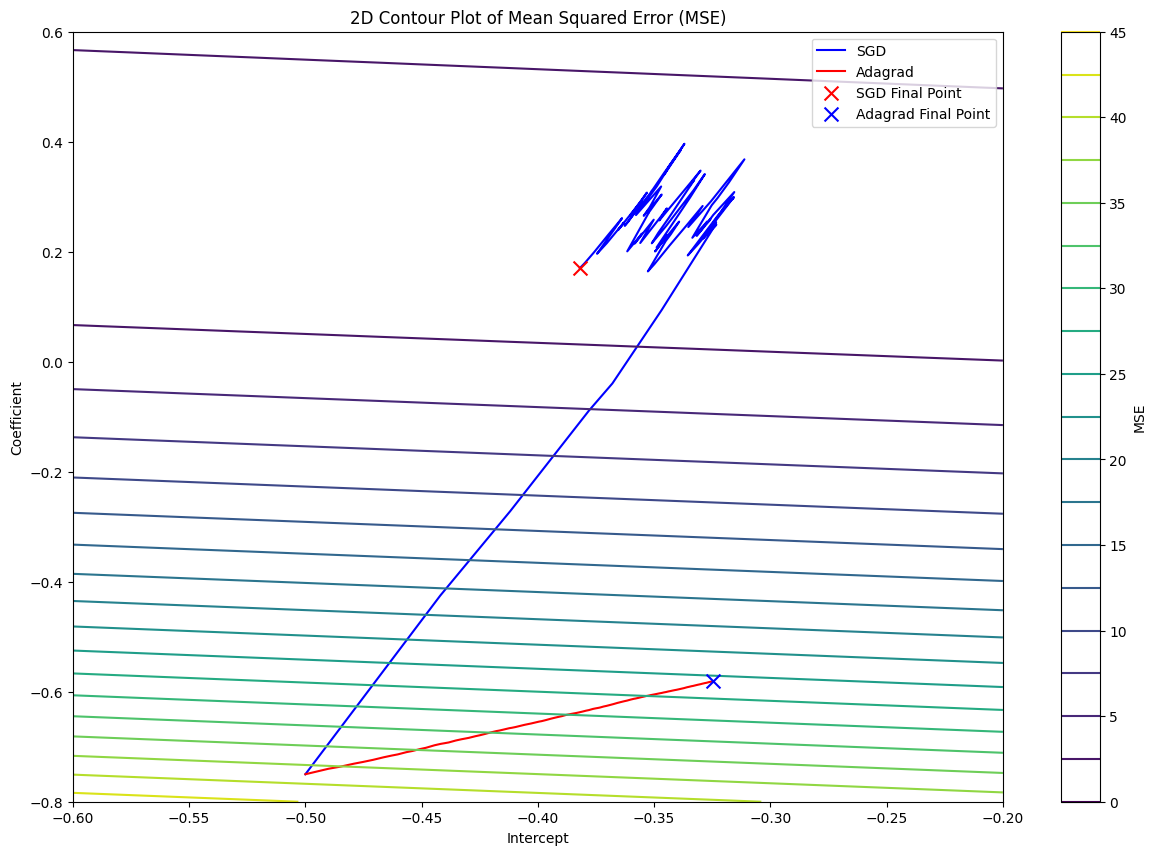
You would notice that SGD have reached the bottom of the valley faster than Adagrad in less than iterations.
Unlike SGD, Adagrad required more iterations to reach the bottom of the valley. The reason is Adagrad’s aggressive learning rate decay over time. In other words, the learning rate decreases as the number of iterations increases.
Let’s look at the following part in the Adagrad’s parameter update equation:
Remember that represents accumulated_squared_intercept_gradient and accumulated_squared_coefficient_gradient up to time .
As the number of iterations increases, the accumulated sum increases, and the learning rate would decrease significantly over time.
For Adagrad to reach the bottom of the valley faster, epochs should be set to .
def adagrad(x, y, df, epochs = 100, learning_rate = 0.01, eps=1e-8): intercept, coefficient = -0.5, -0.75 accumulated_squared_intercept = 0.0 accumulated_squared_coefficient = 0.0
random_index = np.random.randint(len(features)) prediction = predict(intercept, coefficient, x[random_index]) mse = ((prediction - y[random_index]) ** 2) / 2 df.loc[0] = [intercept, coefficient, mse]
for epoch in range(1, epochs + 1): random_index = np.random.randint(len(features)) prediction = predict(intercept, coefficient, x[random_index]) error = prediction - y[random_index]
intercept_gradient = error coefficient_gradient = error * x[random_index]
accumulated_squared_intercept += intercept_gradient ** 2 accumulated_squared_coefficient += coefficient_gradient ** 2
intercept -= (learning_rate / np.sqrt(accumulated_squared_intercept + eps)) * intercept_gradient coefficient -= (learning_rate / np.sqrt(accumulated_squared_coefficient + eps)) * coefficient_gradient
mse = (error ** 2) / 2 df.loc[epoch] = [intercept, coefficient, mse]
return df