Tech stack: Gradio, HuggingFace, Llama 3.1, Llama Index, Ollama, Python, and ElasticSearch
Update:
- Developed a user interface using Gradio.
- Incorporated a vector embedding database to improve the efficiency of the retrieval process.
- Instead of analyzing the current job openings, I decided to develop a RAG system that summarizes books.
- Stored each book's metadata into the vector database.
- Changed Llama 3.0 to Llama 3.1.
TL;DR: A local book RAG system powered by Llama3.1, Llama Index, and a vector embedding, allowing users to retrieve information and summaries with or without books' metadata. The retrieval processes can be done on a UI for ease of use. Even though this system is capable of providing relatively accurate responses, this RAG system is still generating summaries in real time. Meaning that the system has to go through thousand of chunks of documents whenever users ask for book summaries, and it's considered computationally expensive.
Introduction
This project is a local Retrieval Augmented Generation (RAG) system that retrieves and summarizes books. Since I have over 200 books in my library, I often find it difficult to discover interesting readings.
I created this project to help me summarize books that I have never read before. If the summary is interesting, I would consider spend time reading the book. If not, I would love to just read the summary of each chapter of the book.
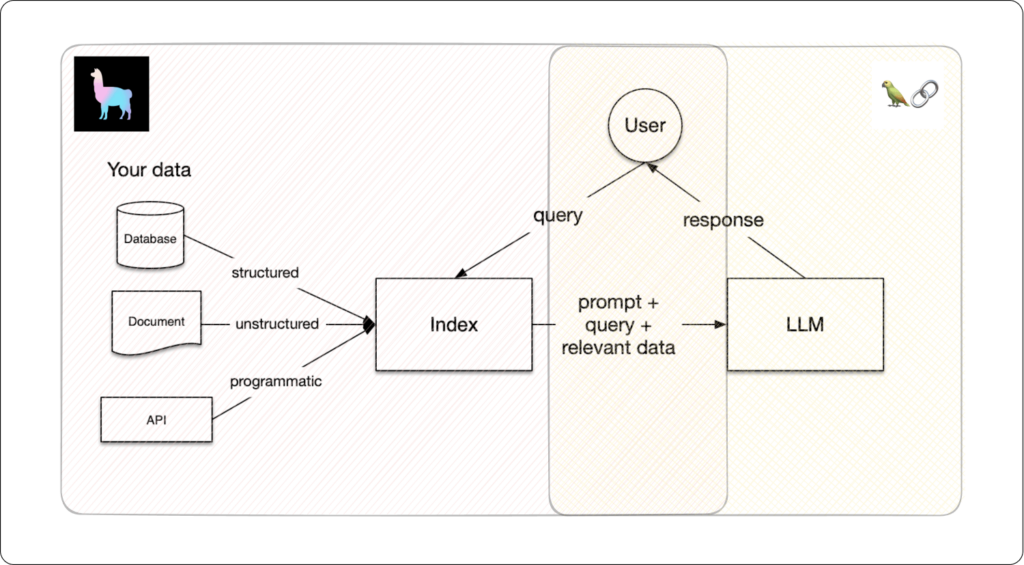 What Llama Index and Langchain focus on (Source: https://superwise.ai/blog/lets-talk-about-llamaindex-and-langchain/)
What Llama Index and Langchain focus on (Source: https://superwise.ai/blog/lets-talk-about-llamaindex-and-langchain/)
Why Llama Index? From the figure above, Llama Index focuses on the indexing, storing, and retrieving data. While Langchain focuses on prompting and the output of the query. Since I am only focusing on indexing and retrieving data, I am going to incorporate Llama Index only for this project.
Why would we need RAG? According to Llama Index, RAG helps processing and adding external or personal data in the generation process. Adding this external data can help the model to generate more relevant and accurate responses. However, adding this external data to the model requires five stages: loading, indexing, storing, querying, and evaluation.
In order to get the local RAG system to work, three components are needed: an embedding model, a vector index, and a retrieval model.
Note that LLM models process information in chunks. If documents are too long, the model may be slow to find relevant or, worse, not be able to process them due to memory constraints. If too short, the model would generate irrelevant responses, or halluciante, due to lack of context.
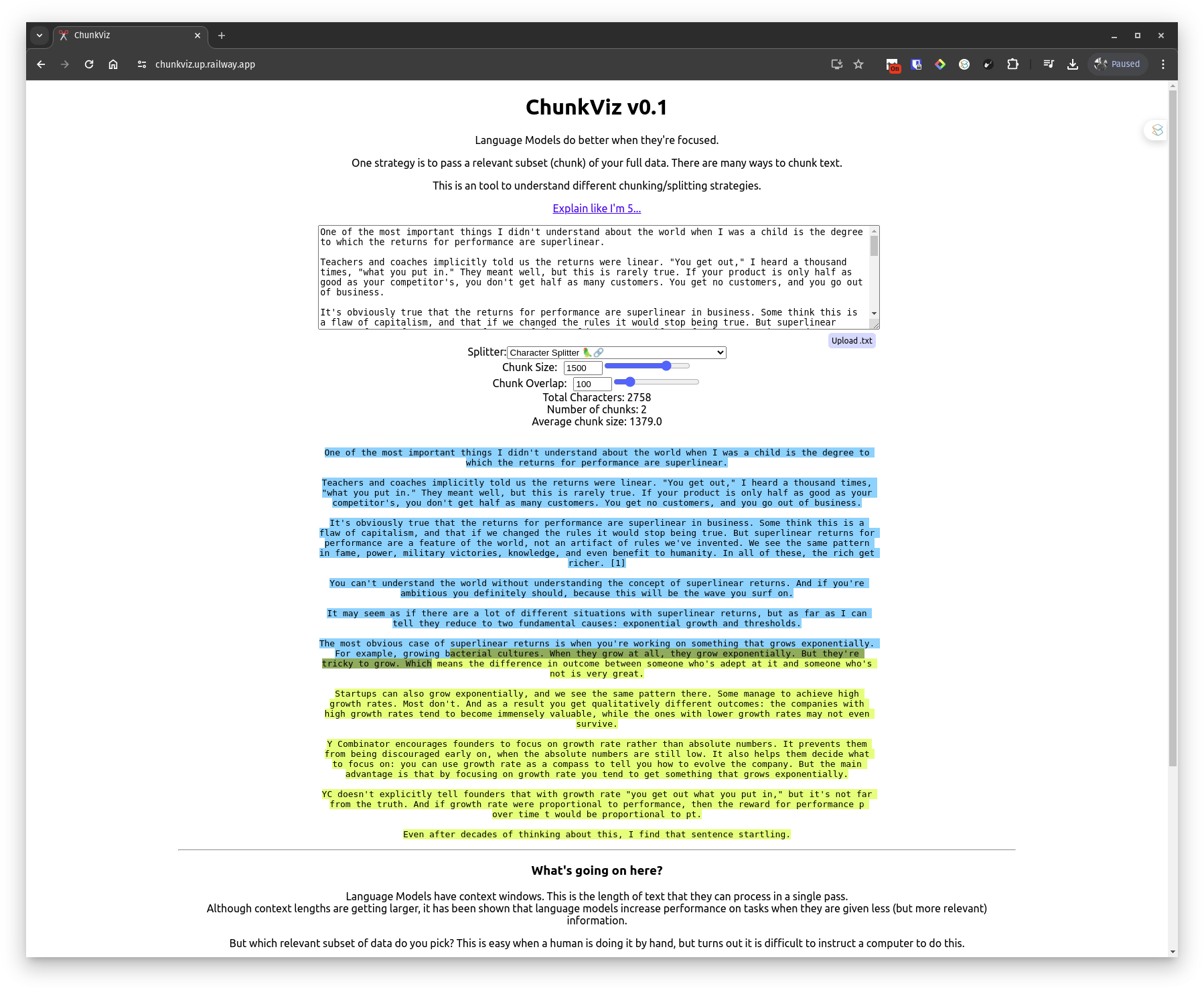 1024 chunk size, and 100 chunk overlap
1024 chunk size, and 100 chunk overlap
https://chunkviz.up.railway.app/ can help visualize the chunking process.
Since I am dealing with .epub files, each document would be seperated into a chunk of 1024 words.
Thus, each document would have different number of chunks.
Limitations
Initially, these are the limitations of the RAG system:
No UI
It is challenging for users who do not have a technical background to interact with the RAG system since it was only accessible via the command line.
Insufficent Memory
Llama Index converts documents into vector embeddings and stores them in memory by default. This will be a problem if the number of documents increases.
Limited Control
The RAG system is only capable of retrieving job descriptions from 2-3 documents at a time. That is the default setting of Llama Index. User should be able to have more control over how many documents and how the documents are retrieved.
Documents Not Found
In some cases, the model responds with "No documents found" even though the documents are in the vector database. This is due to each document not having metadata.
Hallucination
In the case of this project, the model produces irrelevent responses even though the one of the documents retrieved is relevant. I later found out that, as the number of retrieved documents increases, the model is sometimes lost in contexts and generate irrelevant responses because the retrieval model has to combine the retrieved documents into a big chunk of text before passing them it into the language model.
I also tried the refine mode to generate responses.
However, the model also generates irrelevant reponses as well.
The reason being is the model refines its response as it sees a new document.
Meaning, if there were 5 documents retrieved, the model will refine its response 5 times.
In addition to that, the generation process is slower since the model has to generate 5 different responses.
Realtime Summarization
It's computationally expensive to retrieve information from thousand relevant chunks of documents and generate summarizations in real time whenever users ask for book summaries. So, it's better to have a separate database that stores each book's summary in a few paragraphs.
Improvements
User Interface
To improve the user experience, I created a web interface for the RAG system using Gradio.
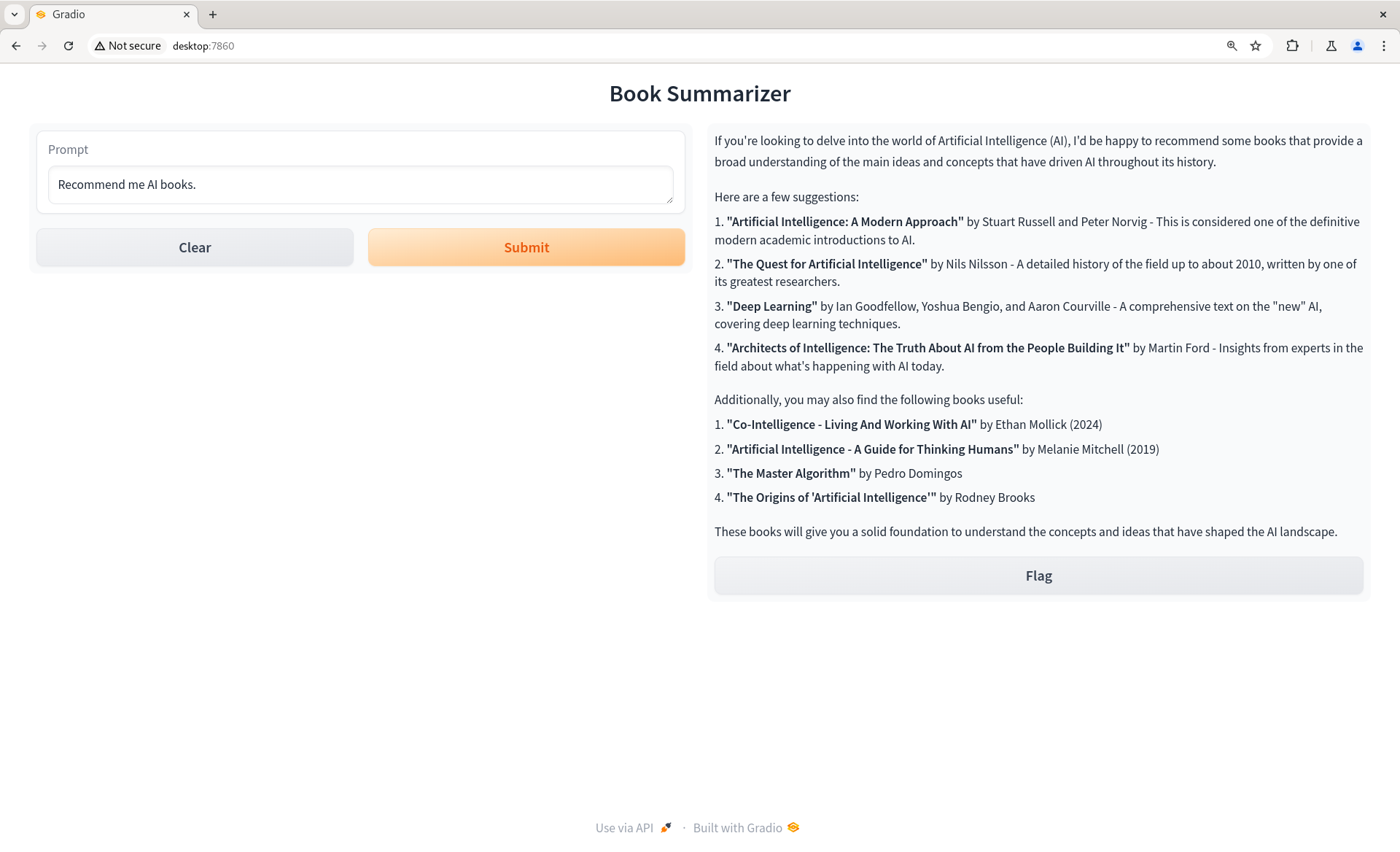 Initial RAG UI
Initial RAG UI
Vector Database
In order to improve the efficiency of retrieval processes, I incorporated Weaviate, a vector database, to store the documents that have been converted into vector embeddings. Not only the RAM usage is reduced significantly, but the retrieval process is generally faster.
More Control
From the figure above, you can see that uses can determine how many relevant documents they want to retrieve, as well as how the retrieval processes should be done.
The alpha parameter is used to determine the retrieval mode of the model. If the alpha parameter is 0, the model will retrieve data using the bm25 approach, meaning the model will retrieve data based on the similarity of the query and the document.
If the alpha parameter is 1, the model will retrieve data using the vector approach, meaning the model will retrieve data based on the similarity of the query and the vector embeddings. By default, the alpha parameter is set to .
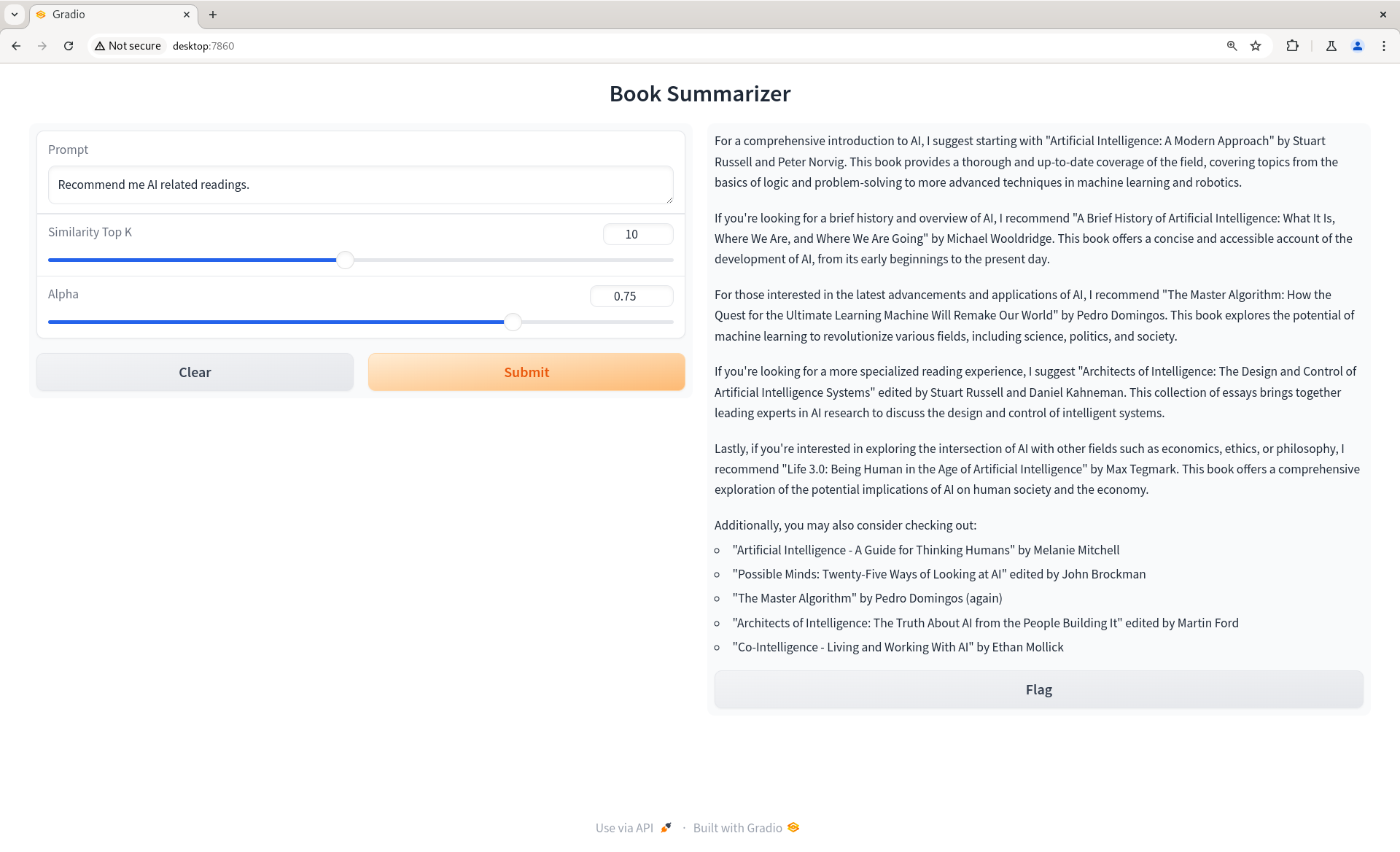 RAG UI with search settings
RAG UI with search settings
Precise Retrieval
Since each document has metadata, users can search documents accurately based on titles and authors. Thus, the retrieval model can retrieve corrent details from the correct documents so that the language model provides accurate facts or summarizations in its responses.
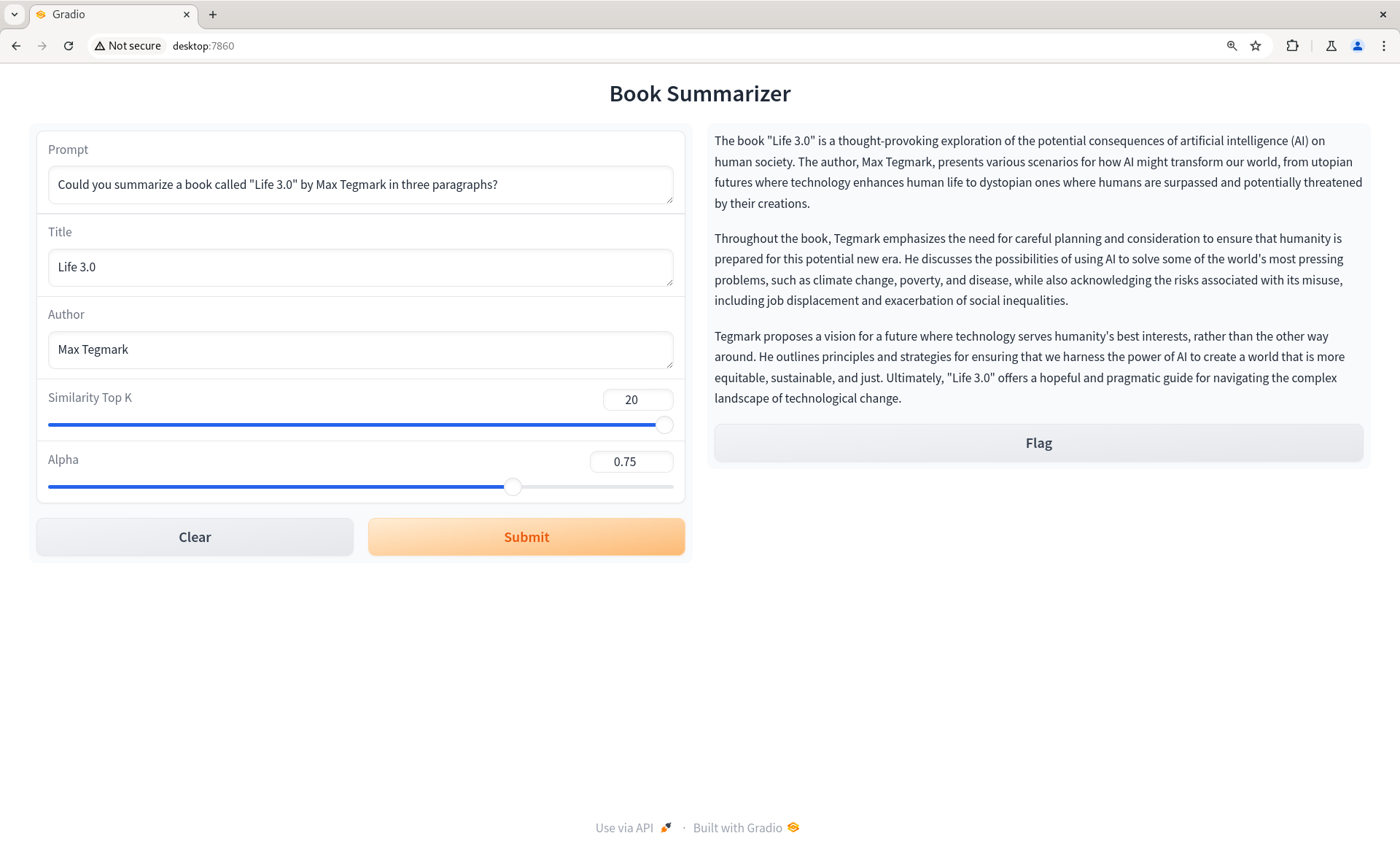 RAG UI with metadata search and search settings
RAG UI with metadata search and search settings
Better Responses
By default, the model retrieves documents using compact mode.
Meaning the model will combine texts into a big chunk of text and compose the relevant answer.
However, this mode is very accurate when the number of documents is small.
Conversely, the model may produce irrelevant responses as the number of documents increases.
To fix this issue, the model should use the tree_summarize mode.
From the codebase tells me, this is what it does:
Build a tree index over the set of candidate nodes, with a summary prompt seeded with the query. The tree is built in a bottoms-up fashion, and in the end the root node is returned as the response.
Challenges
Weaviate
Given Weaviate is a new technology, I am hesitant to invest in it Unlike ElasticSearch who has been in the game for many years, Weaviate community is still small, and it's quite challenging for me to find threads or forums that discuss issues that I am facing while using Weaviate.
The only issue I had is when I wanted to implement the metadata filter for books using Llama Index. At the end, I noticed that each metadata of a book is stored together along with its text after getting chunked, making the metadata filter challenging to implement.
User Interface
The UI looks nice as a prototype. I personally think the UI can be improved so that users can see which documents are used for the response generation and see the referenced documents side by side.
Parameters
The user interface contains many parameters that users can adjust, and not many users would understand what each parameter does. In the next iterations, I would like to reduce the number of parameters that users can see and interact with.